MonoDepth-vSLAM: Visual SLAM with Deep Learning Depth Estimation

Overview
Autonomous navigation in GPS-denied environments presents one of the most challenging problems in robotics. While LiDAR-based systems provide accurate 3D mapping, they remain expensive and power-intensive. This project explores a more accessible alternative: vision-only SLAM using a single monocular camera.
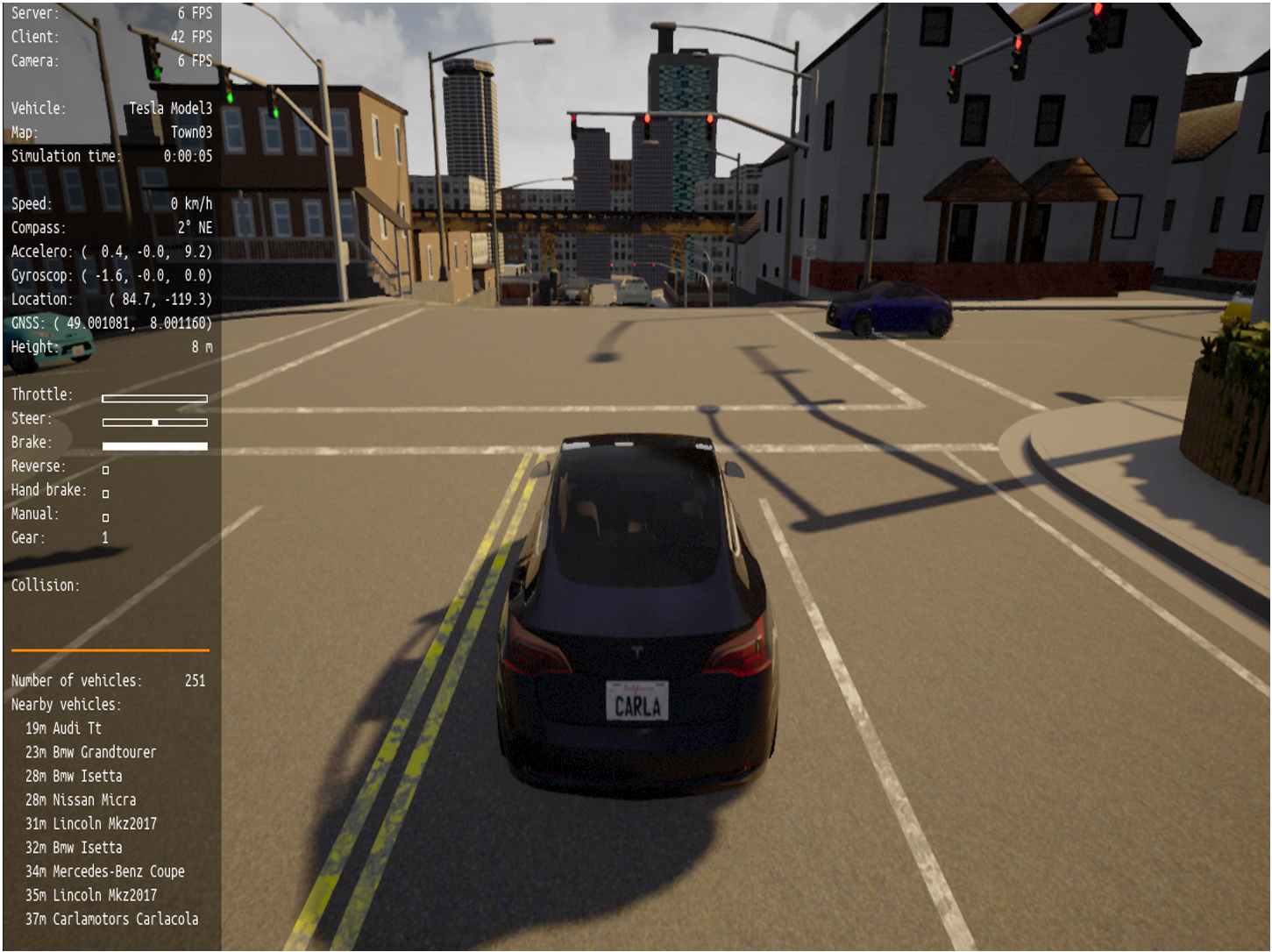 Figure 1: CARLA simulator setup.
Figure 1: CARLA simulator setup.
I developed MonoDepth-vSLAM, a hybrid system that combines classical Extended Kalman Filter (EKF) state estimation with modern deep learning-based depth perception. The result is a lightweight, real-time localization and mapping framework that operates on consumer-grade hardware while maintaining accuracy comparable to traditional sensor-rich systems.
The Challenge: Scale Ambiguity in Monocular Vision
Unlike stereo cameras or LiDAR, a single camera cannot directly measure depth. This creates the infamous scale ambiguity problem—the inability to distinguish between a small object nearby and a large object far away from a single 2D image.
In traditional monocular SLAM, this leads to:
- Unobservable state vectors: The EKF cannot converge without absolute depth measurements
- Scale drift: The estimated map gradually shrinks or expands over time
- Trajectory divergence: Position estimates become increasingly unreliable
Key Technical Challenges
- Depth Recovery: How do we extract metric depth from a single image without expensive sensors?
- Sensor Fusion: How do we integrate non-linear deep learning predictions into a linear-Gaussian filter?
- Real-Time Performance: Can this run at camera frame rates (30+ FPS) on standard hardware?
System Architecture
The system follows a modular, hybrid architecture that leverages the strengths of both classical robotics and modern AI.
Pipeline Overview
1
Camera Input → Feature Detection → Depth Estimation → EKF Prediction → Data Association → EKF Update → Pose & Map Output
Core Components:
- Vision Frontend: ORB feature detector identifies keypoints in each frame
- Depth Network: Self-supervised CNN predicts dense depth maps
- EKF Backend: Fuses visual measurements with motion model for state estimation
- Loop Closure: Detects revisited locations to correct accumulated drift
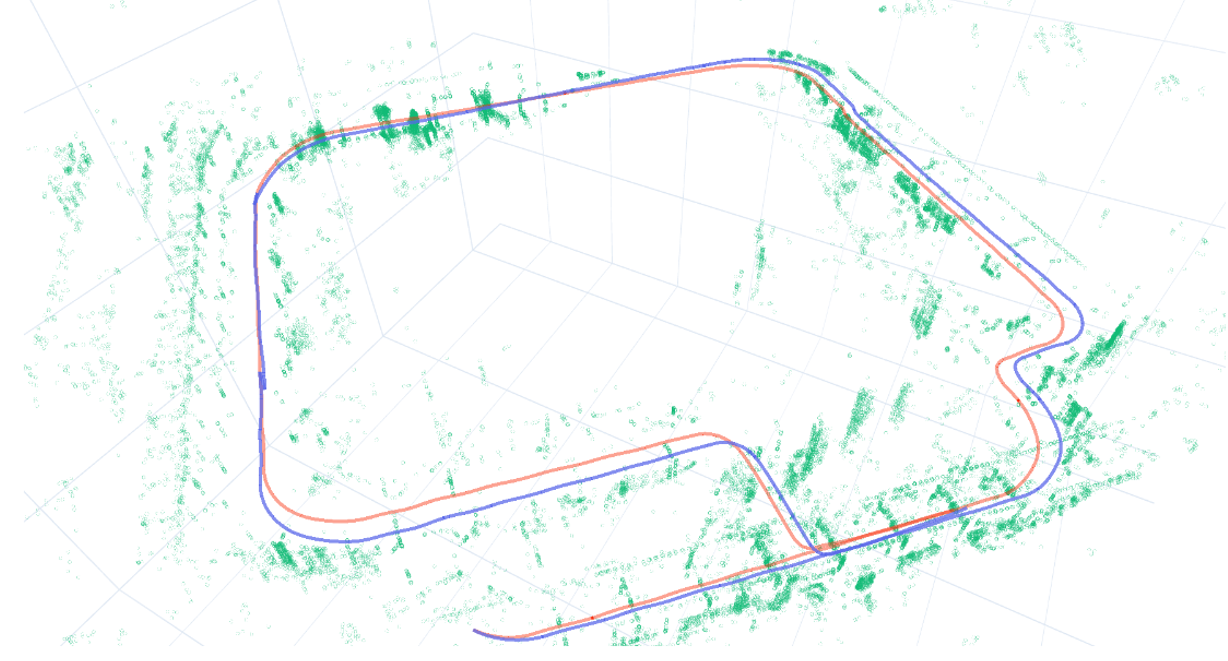 Figure 2: Real-time SLAM output showing feature tracking, depth estimation, and trajectory estimation in CARLA simulator.
Figure 2: Real-time SLAM output showing feature tracking, depth estimation, and trajectory estimation in CARLA simulator.
Methodology
1. Motion Model: Constant Velocity and Turn Rate (CVTR)
The vehicle is modeled as an Ackermann steering platform with state vector:
\[\mathbf{x}_v = [x, y, \theta, v, \omega]^T\]Where:
- $(x, y, \theta)$ represent the vehicle’s 2D pose
- $v$ is the forward velocity
- $\omega$ is the angular (yaw) rate
The motion evolves under Gaussian process noise, capturing uncertainties in acceleration and steering input.
2. Optical Flow-Based Observation Model
Features tracked in the image plane move according to the camera’s ego-motion. For a camera with planar motion (forward translation $V_{z_c}$ and yaw rotation $\omega_{y_c}$), the pixel velocity is given by:
\[\begin{bmatrix} \dot{u} \\ \dot{v} \end{bmatrix} = \begin{bmatrix} -\frac{u}{Z_c} & \frac{F^2 + u^2}{F} \\ -\frac{v}{Z_c} & \frac{u \cdot v}{F} \end{bmatrix} \begin{bmatrix} V_{z_c} \\ \omega_{y_c} \end{bmatrix}\]Where:
- $(u, v)$ are pixel coordinates
- $Z_c$ is feature depth (from the CNN)
- $F$ is the camera focal length
This model allows the EKF to predict where features will appear in the next frame, enabling:
- Efficient data association (reduced search space)
- Outlier rejection (features outside prediction gates)
- Consistency checks (Mahalanobis distance gating)
3. Intelligent Feature Tracking with ORB
ORB (Oriented FAST and Rotated BRIEF) was chosen for its:
- Rotation invariance (handles vehicle turns)
- Computational efficiency (~1 ms per frame)
- Robustness to lighting changes
Innovation: Instead of brute-force matching across the entire image, I implemented covariance-guided search windows. The EKF’s uncertainty ellipse defines a probabilistic region where the feature is expected to reappear, dramatically reducing false matches and computational load.
4. Self-Supervised Depth Estimation Network
The depth network is based on MonoDepth2, a ResNet-18 encoder with a U-Net decoder featuring skip connections.
Training Strategy:
- Dataset: 30,000 stereo image pairs from CARLA Simulator (Towns 1-5)
- Loss Function: Photometric reconstruction error + edge-aware smoothness
- Self-Supervision: No ground-truth depth labels required—the network learns by predicting one stereo view from the other
Why This Works:
The key insight is that stereo image pairs provide implicit depth supervision through epipolar geometry. By minimizing the reprojection error between left and right images, the network learns to predict accurate metric depth.
Architecture Benefits:
- Skip connections preserve high-frequency spatial details
- Multi-scale predictions handle both near and far objects
- Inference time: ~15 ms per frame on RTX 2060
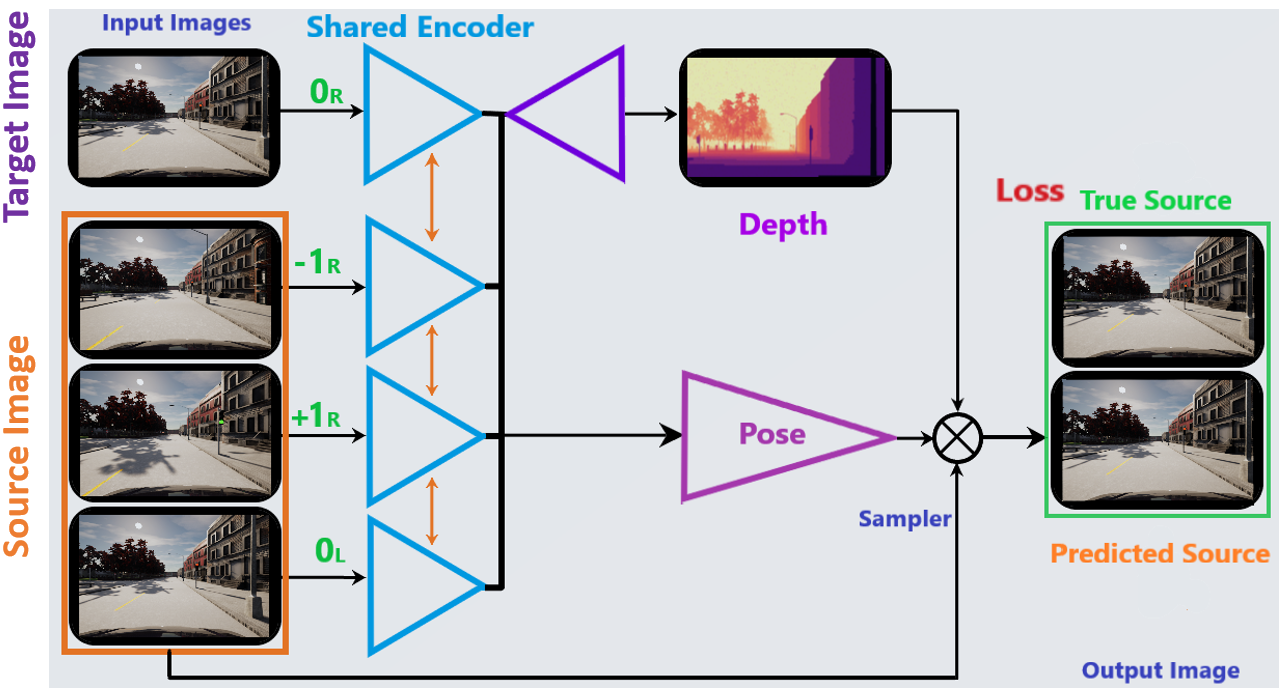 Figure 3: Self-supervised depth estimation network architecture based on MonoDepth2 with ResNet-18 encoder and U-Net decoder.
Figure 3: Self-supervised depth estimation network architecture based on MonoDepth2 with ResNet-18 encoder and U-Net decoder.
Experimental Validation
Testing Environment: CARLA Simulator
All experiments were conducted in CARLA Town03, a realistic urban environment with:
- Multi-lane roads with traffic
- Pedestrian crossings
- Complex intersection geometry
- Varying lighting conditions
Test Configuration:
- Vehicle: Tesla Model 3 (simulated Ackermann dynamics)
- Camera: 640×480 RGB, 30 FPS, 90° FOV
- Trajectory Length: 1.5 km
- Total Frames Processed: ~9,500
 Figure 4: Live demonstration of MonoDepth-vSLAM navigating through CARLA Town03, showing real-time feature tracking and localization.
Figure 4: Live demonstration of MonoDepth-vSLAM navigating through CARLA Town03, showing real-time feature tracking and localization.
Performance Metrics
| Metric | Value | Significance |
|---|---|---|
| Translation Drift | ±10 m over 1.5 km | <0.67% error relative to distance traveled |
| Rotation Error | ±5° | Maintains heading accuracy through multiple turns |
| Feature Tracking | 85% retention rate | Most features tracked for >20 frames |
| Frame Rate | 32 FPS average | Real-time capable on consumer GPU |
 Figure 5: Examples of RGB camera input and corresponding depth map predictions from the MonoDepth2 network.
Figure 5: Examples of RGB camera input and corresponding depth map predictions from the MonoDepth2 network.
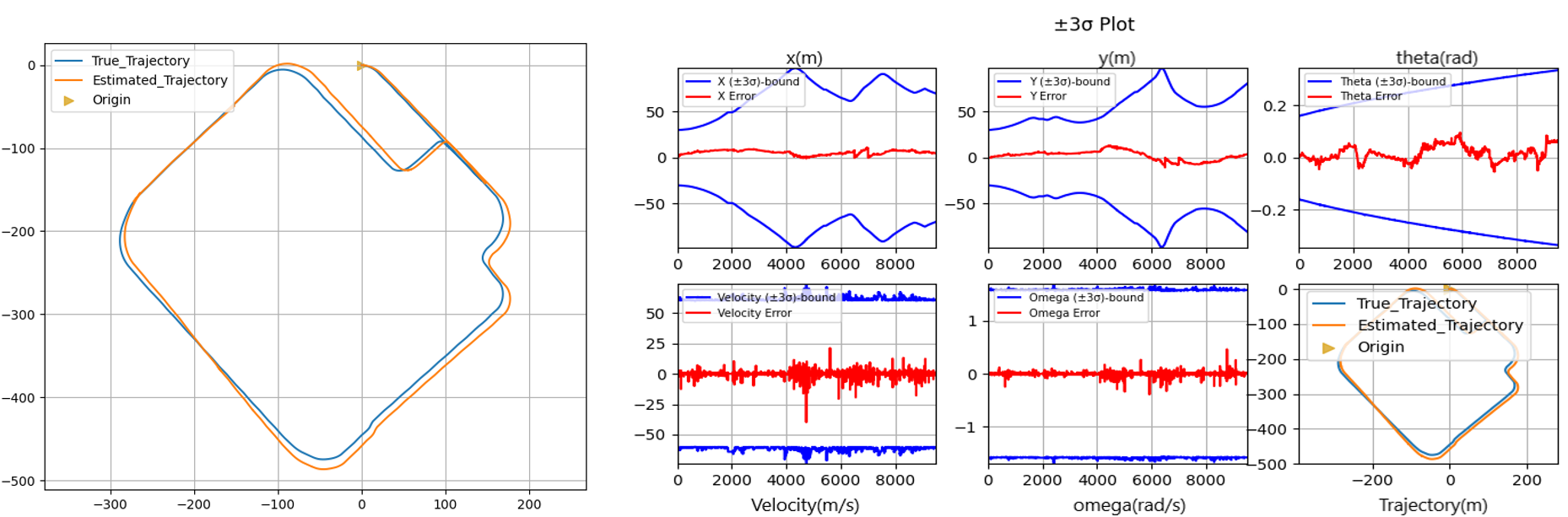 Figure 6: Quantitative analysis showing trajectory comparison and error metrics over the complete test run.
Figure 6: Quantitative analysis showing trajectory comparison and error metrics over the complete test run.
Loop Closure Validation
In Town02 (a circular track with multiple loops), the system successfully:
- Detected loop closures using visual bag-of-words
- Corrected accumulated drift by distributing error across the trajectory
- Reduced map uncertainty by re-observing landmarks
The trajectory estimate snapped back to ground truth with sub-meter accuracy after loop closure, demonstrating the system’s ability to maintain long-term consistency.
Key Contributions
This project makes several important contributions to the field of visual SLAM:
Hybrid Architecture: Demonstrates that classical probabilistic filters can be successfully augmented with deep learning without sacrificing interpretability or reliability
Scale Observability: Resolves the monocular scale ambiguity problem through self-supervised depth learning, eliminating the need for additional sensors
Computational Efficiency: Achieves real-time performance on consumer hardware by intelligent algorithm design (covariance-guided search, efficient feature descriptors)
Practical Viability: Validates the system in a realistic simulator with complex dynamics, showing readiness for real-world deployment
Limitations and Future Work
While the system performs well in structured environments, several areas warrant further investigation:
- Dynamic Objects: The current system assumes a static world; moving vehicles and pedestrians can cause outliers
- Lighting Invariance: Depth network struggles with extreme darkness or oversaturation
- Semantic Understanding: Adding object recognition could improve data association and enable semantic mapping
Future Directions:
- Integration of semantic segmentation for object-level SLAM
- Multi-session mapping for long-term autonomy
- Hardware deployment on embedded platforms (NVIDIA Jetson)
- Real-world testing with physical vehicles
Technical Implementation
Software Stack
| Component | Technology |
|---|---|
| Simulation | CARLA 0.9.13 (Unreal Engine 4) |
| Deep Learning | PyTorch 1.10, torchvision |
| Computer Vision | OpenCV 4.5 (feature detection, optical flow) |
| State Estimation | Custom Python EKF implementation |
| Visualization | Matplotlib, RViz |
Hardware Specifications
- GPU: NVIDIA RTX 2060 (6GB VRAM)
- CPU: Intel Core i7-9750H
- RAM: 16 GB DDR4
Conclusion
MonoDepth-vSLAM demonstrates that vision-only navigation is not only feasible but can be highly accurate when classical state estimation is thoughtfully combined with modern perception. By solving the scale ambiguity problem through self-supervised depth learning, the system achieves localization performance comparable to more expensive sensor suites.
This work represents a significant step toward democratizing autonomous navigation—making robust SLAM accessible to platforms where cost, weight, or power consumption prohibit the use of LiDAR. The techniques developed here have direct applications in:
- Warehouse robotics and AGVs
- Drone navigation in GPS-denied indoor environments
- Low-cost autonomous vehicle research platforms
- Augmented reality and 3D reconstruction
The success of this hybrid approach opens exciting avenues for future research at the intersection of classical robotics and deep learning.